Синонимы к словосочетанию «семантическое ядро»

Прямых синонимов не найдено.
Связанные слова и выражения
- страница результатов поиска
- ключевое слово
- качественный контент
- показатель отказов
- воронка продаж
- автоматизация маркетинга
- бесплатный хостинг
- автономный блог
- сценарий использования
- продвижение сайта
- рекламное сообщение
- уровень приложения
- язык разметки
- шаблон проектирования
- авторизованный пользователь
- эффективность рекламы
- доменное имя
- редактирование изображений
- двойное расходование
- интернет магазин
- статистика посещений
- поисковый робот
- поисковое продвижение
- элемент интерфейса
- статистика запросов
Делаем Карту слов лучше вместе

Привет! Меня зовут Лампобот, я компьютерная программа, которая помогает делать
Карту слов. Я отлично
умею считать, но пока плохо понимаю, как устроен ваш мир. Помоги мне разобраться!
Спасибо! Я стал чуточку лучше понимать мир эмоций.
Вопрос: дефлорация — это что-то нейтральное, положительное или отрицательное?
Связанные слова (по тематикам)
- Люди: лингвист, языковед, бомбардир, артиллерист, повествователь
- Места: подмножество, глоссарий, крюйт-камера, мезон, бастион
- Предметы: цитоплазма, пушка, снаряд, картечь, бомбарда
- Действия: унификация, референция, соотнесение, категоризация, формализация
- Абстрактные понятия: эквивалентность, изоморфизм, когерентность, дополнительность, семантика
Ассоциации к слову «семантический»
Ассоциации к слову «ядро»
Предложения со словосочетанием «семантическое ядро»
- Ориентация на смысл требует ручного труда, что делает составление семантического ядра очень трудоёмким.
- Эти слова вы непременно обнаружите, если качественно будете составлять семантическое ядро сайта.
- Представьте, что сбор семантического ядра сайта – это закладка фундамента будущего строения.
- (все предложения)
Цитаты из русской классики со словосочетанием «семантическое ядро»
- В ответ на это с монастырской стены сыпалась картечь и летели чугунные ядра. Не знал страха Гермоген и молча делал свое дело. Но случилось и ему испугаться. Задрожали у инока руки и ноги, а в глазах пошли красные круги. Выехал как-то под стену монастырскую сам Белоус на своем гнедом иноходце и каким-то узелком над головой помахивает. Навел на него пушку Гермоген, грянул выстрел — трое убито, а Белоус все своим узелком машет.
- В это время с быстрым неприятным шипением пролетает неприятельское ядро и ударяется во что-то; сзади слышен стон раненого. Этот стон так странно поражает меня, что воинственная картина мгновенно теряет для меня всю свою прелесть; но никто, кроме меня, как будто не замечает этого: майор смеется, как кажется, с большим увлечением; другой офицер совершенно спокойно повторяет начатые слова речи; генерал смотрит в противоположную сторону и со спокойнейшей улыбкой говорит что-то по-французски.
- И, скажу вам, засуха стояла тогда такая, что никто и не запомнит; в воздухе не то дым, не то туман, пахнет гарью, мгла, солнце, как ядро раскаленное, а что пыли — не прочихнешь!
- (все
цитаты из русской классики)
Значение словосочетания «семантическое ядро»
-
Семантическое ядро сайта — это упорядоченный набор слов, их морфологических форм и словосочетаний, которые наиболее точно характеризуют вид деятельности, товары или услуги, предлагаемые сайтом. Семантическое ядро имеет центральное ключевое слово, как правило высокочастотное, и все остальные ключевые слова в нём ранжируются по мере убывания частоты совместного использования с центральным запросом в общей коллекции документов. Таким образом, семантическое ядро представляется в виде семантического графа, где длины его ребер обратно пропорциональны частоте совместного упоминания. (Википедия)
Все значения словосочетания СЕМАНТИЧЕСКОЕ ЯДРО
Афоризмы русских писателей со словом «ядро»
- Сквозь тысячу лет бытия на горестной земле борьбы, трудов, войн, преступлений — немеркнущее духовное ядро, живое сердце — вот интуиция Родины.
- Нам в жизни сделать многое дано.
Я подымаю доброе вино
за новый год, за новые победы,
за жизнь, за новые ее приметы,
за песню тракториста на заре,
где степь спала в ковыльном серебре,
за новые глубины в атомном ядре,
за новостройки и за новоселья,
за новорожденных в этом году,
за честное застольное веселье,
за новый сорт в мичуринском саду,
за новую открытую звезду…
В одном лишь должен отклониться я —
я пью за старую любовь, друзья. - (все афоризмы русских писателей)
Отправить комментарий
Дополнительно
Смотрите также
Семантическое ядро сайта — это упорядоченный набор слов, их морфологических форм и словосочетаний, которые наиболее точно характеризуют вид деятельности, товары или услуги, предлагаемые сайтом. Семантическое ядро имеет центральное ключевое слово, как правило высокочастотное, и все остальные ключевые слова в нём ранжируются по мере убывания частоты совместного использования с центральным запросом в общей коллекции документов. Таким образом, семантическое ядро представляется в виде семантического графа, где длины его ребер обратно пропорциональны частоте совместного упоминания.
Все значения словосочетания «семантическое ядро»
-
Ориентация на смысл требует ручного труда, что делает составление семантического ядра очень трудоёмким.
-
Эти слова вы непременно обнаружите, если качественно будете составлять семантическое ядро сайта.
-
Представьте, что сбор семантического ядра сайта – это закладка фундамента будущего строения.
- (все предложения)
- семантика
- (ещё ассоциации…)
- земля
- квазар
- пушка
- орех
- центр
- (ещё ассоциации…)
- семантическое поле
- семантическое ядро
- семантическая сеть
- (полная таблица сочетаемости…)
- атомное ядро
- ядро атома
- деление ядра
- ядро распадается
- составлять ядро
- (полная таблица сочетаемости…)
- Разбор по составу слова «семантический»
- Разбор по составу слова «ядро»
- Как правильно пишется слово «семантический»
- Как правильно пишется слово «ядро»
На букву С Со слова «семантическое»
Фраза «семантическое ядро»
Фраза состоит из двух слов и 17 букв без пробелов.
- Синонимы к фразе
- Написание фразы наоборот
- Написание фразы в транслите
- Написание фразы шрифтом Брайля
- Передача фразы на азбуке Морзе
- Произношение фразы на дактильной азбуке
- Остальные фразы со слова «семантическое»
- Остальные фразы из 2 слов
 06:27
06:27
Что такое семантическое ядро? Как собрать семантическое ядро? Рассказываем простыми словами
 29:15
29:15
Как составить семантическое ядро (Примеры группировки и сервисы) | SEOquick
 49:23
49:23
Сбор семантического ядра от А до Я (Инструкция для новичков)
 38:41
38:41
Составление семантического ядра, сбор статистики — Урок №3, Школа SEO
 44:16
44:16
Как собрать семантическое ядро для сайта: бесплатно и правильно с нуля
 06:26
06:26
Как составить семантическое ядро? 5 способов собрать семантическое ядро.
Синонимы к фразе «семантическое ядро»
Какие близкие по смыслу слова и фразы, а также похожие выражения существуют. Как можно написать по-другому или сказать другими словами.
Фразы
- + автоматизация маркетинга −
- + автономный блог −
- + авторизованный пользователь −
- + бесплатный хостинг −
- + воронка продаж −
- + двойное расходование −
- + доменное имя −
- + интернет магазин −
- + качественный контент −
- + ключевое слово −
- + поисковое продвижение −
- + поисковый робот −
- + показатель отказов −
- + продвижение сайта −
- + редактирование изображений −
- + рекламное сообщение −
- + статистика запросов −
- + статистика посещений −
- + страница результатов поиска −
- + сценарий использования −
- + уровень приложения −
- + шаблон проектирования −
- + элемент интерфейса −
- + эффективность рекламы −
Ваш синоним добавлен!
Написание фразы «семантическое ядро» наоборот
Как эта фраза пишется в обратной последовательности.
ордя еоксечитнамес 😀
Написание фразы «семантическое ядро» в транслите
Как эта фраза пишется в транслитерации.
в латинской🇬🇧 semanticheskoye yadro
Как эта фраза пишется в пьюникоде — Punycode, ACE-последовательность IDN
xn--80ajbannkjmwgj0e xn--d1auf2d
Как эта фраза пишется в английской Qwerty-раскладке клавиатуры.
ctvfynbxtcrjtzlhj
Написание фразы «семантическое ядро» шрифтом Брайля
Как эта фраза пишется рельефно-точечным тактильным шрифтом.
⠎⠑⠍⠁⠝⠞⠊⠟⠑⠎⠅⠕⠑⠀⠫⠙⠗⠕
Передача фразы «семантическое ядро» на азбуке Морзе
Как эта фраза передаётся на морзянке.
⋅ ⋅ ⋅ ⋅ – – ⋅ – – ⋅ – ⋅ ⋅ – – – ⋅ ⋅ ⋅ ⋅ ⋅ – ⋅ – – – – ⋅ ⋅ – ⋅ – – ⋅ ⋅ ⋅ – ⋅ – – –
Произношение фразы «семантическое ядро» на дактильной азбуке
Как эта фраза произносится на ручной азбуке глухонемых (но не на языке жестов).
Передача фразы «семантическое ядро» семафорной азбукой
Как эта фраза передаётся флажковой сигнализацией.













Остальные фразы со слова «семантическое»
Какие ещё фразы начинаются с этого слова.
- семантическое значение
- семантическое насыщение
- семантическое отношение
- семантическое поле
- семантическое пространство
- семантическое различие
- семантическое свойство
Ваша фраза добавлена!
Остальные фразы из 2 слов
Какие ещё фразы состоят из такого же количества слов.
- а вдобавок
- а вдруг
- а ведь
- а вот
- а если
- а ещё
- а именно
- а капелла
- а каторга
- а ну-ка
- а приятно
- а также
- а там
- а то
- аа говорит
- аа отвечает
- аа рассказывает
- ааронов жезл
- аароново благословение
- аароново согласие
- аб ово
- абажур лампы
- абазинская аристократия
- абазинская литература
Комментарии
 @zzew 06.01.2020
@zzew 06.01.2020 09:47
Что значит фраза «семантическое ядро»? Как это понять?..
Ответить
@eugbnrc 04.09.2022 00:13
![]() 1
1
×
![]()
Здравствуйте!
У вас есть вопрос или вам нужна помощь?
![]()
Спасибо, ваш вопрос принят.
Ответ на него появится на сайте в ближайшее время.
А Б В Г Д Е Ё Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я
Транслит Пьюникод Шрифт Брайля Азбука Морзе Дактильная азбука Семафорная азбука
Палиндромы Сантана
Народный словарь великого и могучего живого великорусского языка.
Онлайн-словарь слов и выражений русского языка. Ассоциации к словам, синонимы слов, сочетаемость фраз. Морфологический разбор: склонение существительных и прилагательных, а также спряжение глаголов. Морфемный разбор по составу словоформ.
По всем вопросам просьба обращаться в письмошную.
- Собирать с одного источника
- Упустить синонимы
- Зациклиться на ВЧ-запросах
- Неправильно кластеризовать запросы
- Не учитывать каннибализацию
- Оставить мусор
- Не обновлять семантическое ядро
- Не учитывать событийный трафик
- Выводы
Сбор семантического ядра — одна из первостепенных задач любого SEO-специалиста при работе с проектом, который находится на продвижении. Ниже представлены типичные ошибки, которые могут допустить начинающие оптимизаторы при сборе семантики.
Собирать с одного источника
В семантике, собранной с одного источника, есть возможность упустить ряд запросов, которые помогут продвижению. Мы рекомендуем такой список сервисов для подбора ключевых слов:
- Яндекс.Wordstat;
- Serpstat;
- Букварикс;
- Планировщик ключевых слов — Google Ads;
- Semrush;
- Ahrefs;
- Moab.
Оптимальным вариантом станет ядро, в которое вошли фразы из нескольких источников. С тем, как правильно подобрать ключевые фразы для продвижения, можно детальнее ознакомиться тут.
Упустить синонимы
Семантическое ядро без учёта синонимов будет неполным. При сборе семантики необходимо включать в СЯ синонимы, это поможет повысить релевантность. Например:
- ремонт сотовых телефонов = ремонт мобильных телефонов;
- ретиноевый пилинг = ретиноловый пилинг = жёлтый пилинг.
За синонимами можно заглянуть в поисковую выдачу или использовать Serpstat.
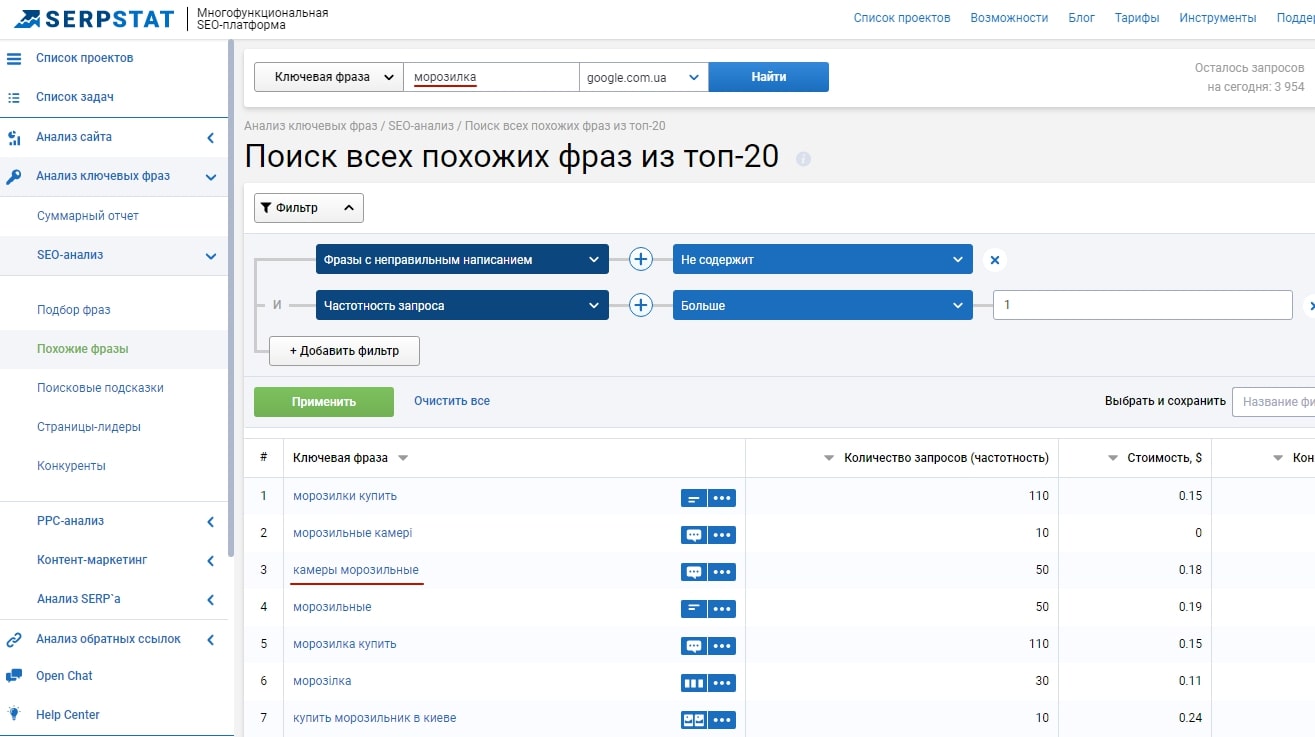
Зациклиться на ВЧ-запросах
Как правило, ВЧ-запросы имеют высокую конкуренцию, продвижение по ним молодого сайта может быть неэффективным. Упускать из вида СЧ и НЧ запросы не стоит. Благодаря им можно подтянуть вектор тематической направленности статей и сайта, что в дальнейшем даст хорошую опору для создания контента, направленного на продвижение по высокочастотным запросам. Продвижение страниц, которые будут ранжироваться по ВЧ-запросам имеет свою специфику.
Неправильно кластеризовать запросы
В случае проведения неправильной кластеризации резко ухудшается релевантность страниц сайта, что негативно сказывается на продвижении. При кластеризации запросов необходимо понять, какой интент пользователи вкладывают в запрос, и правильно распределить запросы по посадочным страницам сайта. Для ускорения этого этапа работы можно использовать сервисы для автоматической кластеризации. В качестве примера можно привести распределение запросов по страницам на тему хранения продуктов в холодильнике с помощью KeyAssort.

Мы видим, что запросы были распределены по кластерам, на основе которых будут созданы страницы. Но не стоит полностью полагаться на автоматизацию процесса. Как показывает практика, некоторые запросы могут попасть не в свою группу или же не смогут занять место ни в одном из кластеров.
Не учитывать каннибализацию
При использовании одних и тех же ключевых фраз для оптимизации на различных страницах происходит потеря релевантности, ухудшаются позиции в выдаче, страницы начинают конкурировать между собой.
Пример каннибализации:
- Страница 1: Сорта томатов для теплиц — Страница 2: Сорта помидоров для теплиц.
- Страница 1: Идеи маникюра для весны 2020 — Страница 2: Модные идеи маникюра для весны и лета 2020.
Для продвижения информационных статей необходимо избегать смысловых дублей страниц, придерживаться принципа: «одна страница — одно фокусное ключевое слово».
Такой проблеме особо подвержены крупные проекты, где из-за стремительного роста количества контента тяжело отследить, использовалась ли ключевая фраза или нет.
Чтобы уйти от проблемы каннибализации, необходимо соблюдать чёткую структуру распределения ключевых слов на сайте, избегать полных смысловых дублей страниц и дублей фокусных ключевых слов.
Оставить мусор
При сборе семантики всегда будут попадаться фразы, которые необходимо исключить из ядра, они будут в лучшем случае неэффективными, а в худшем — мешать продвижению. Краткий список типичного мусора:
- слова с опечатками, спецсимволами;
- фразы, введённые с ошибочной раскладкой клавиатуры;
- нетематические запросы;
- стоп-слова (список бонусом в конце статьи);
- дубли.
Не обновлять семантическое ядро
Собирая семантику в неудачное время года, можно легко упустить приоритетные запросы, которые могут выстрелить лишь в определённом временном промежутке.
Как пример можно привести интерес к теме лучших сортов перца. На графике видно, что частота этого запроса подпрыгивает более чем в 40 раз в зависимости от периода года.
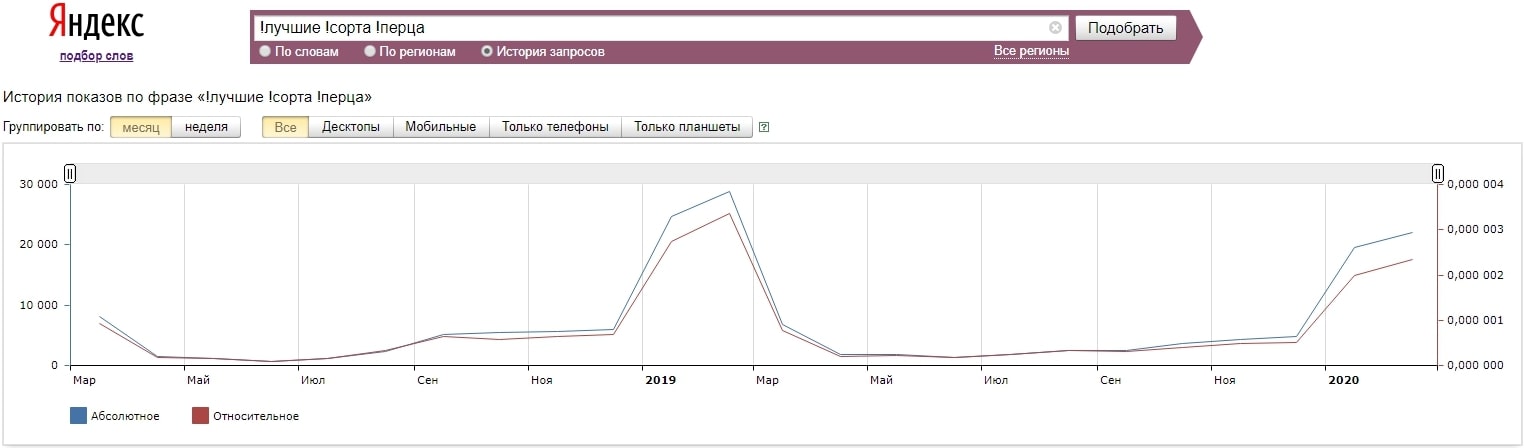
Сезонность является фактором, на который мы не можем влиять, но к которому мы можем подготовиться заблаговременно. Опубликованная на пике интереса к теме статья просто может не успеть быстро проиндексироваться и попадёт в выдачу, когда интерес уже спадёт на нет. Лучше запланировать публикацию за несколько недель до начала стремительного роста популярности запроса.
Не учитывать событийный трафик
Не стоит собирать семантику всего один раз за весь период существования сайта, игнорировать её пополнение новыми запросами и регулярной проверкой их частоты. Важно внимательно следить за интересами своей аудитории и быть в курсе основных тематических событий.
Для событийных запросов характерны резкие всплески интереса к тематике, которые не были ещё так актуальны несколько месяцев назад. Пик попадает непосредственно на дату события, иногда с небольшой временной разбежностью.
К категории событийных запросов можно отнести фразы, связанные с премьерами фильмов, спортивными мероприятиями, конференциями и другими значимыми событиями.
Для примера приведу график роста интереса к шестой части фильма «Терминатор: Тёмные судьбы», который вышел в прокат в последних числах октября 2019 г.
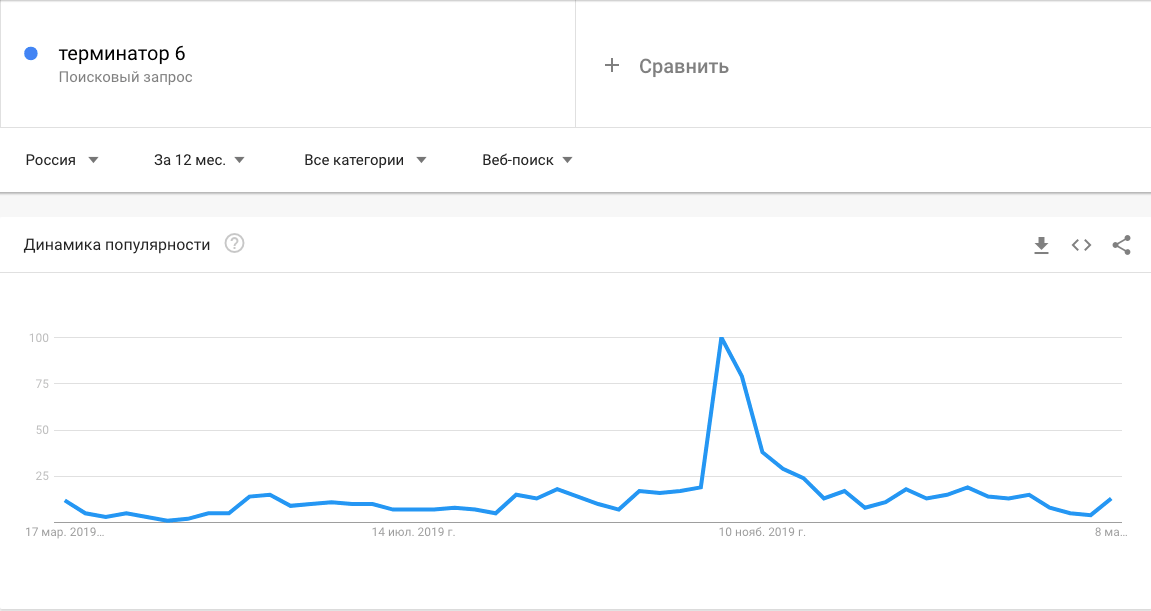
Другим типичным примером также может стать всплеск интереса к теме коронавируса.
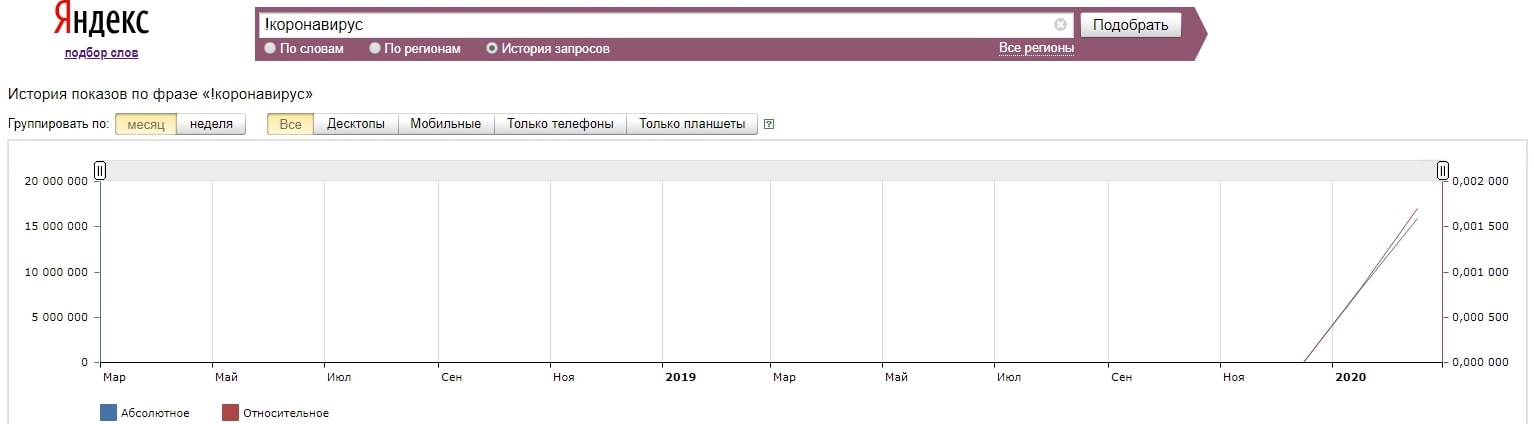
Поймав восходящую волну нарастающего интереса к тематике, можно с прогрессией наращивать трафик, если правильно рассчитать выход публикаций.
Бонус тем, кто дочитал до конца — список стоп слов, которые при необходимости можно исключить при сборе семантики.
Выводы
В заключение хочется отметить важность правильно собранной и сгруппированной семантики. Будущему сайту она поможет иметь высокую релевантность страниц и сайта в целом. Поскольку релевантность страницы имеет значительное влияние на ранжирование, это поможет занять хорошие позиции в выдаче в связке с интересным и качественным контентом.
Paid Traffic Day: все, что нужно знать о платном трафике в 2020!
20 марта наши друзья Академия интернет-маркетинга WebPromoExperts соберут лучших специалистов своего дела, чтобы они рассказали вам всё о таргетированной и контекстной рекламе на бесплатной онлайн-конференции Paid Traffic Day.
Вы услышите доклады: Сергея Вовка (Google), Влада Богуцкого (EVA), Инны Поник (Vodafone Ukraine), Марии Голуб (Netpeak Agency), Алексея Мамонтова (Inweb), Людмилы Беглоян (UAMASTER) и других практикующих экспертов.
Что будет в программе:
- Работа с аудиториями сайта и примеры их применения в Google Ads.
- Как трансформировать рекламный бюджет в прибыль с помощью торговых кампаний?
- Аудит PPC. Как узнать, почему не работает реклама и многое другое!
Участие бесплатное, вам только нужно зарегистрироваться
Также вы можете приобрести запись и пересмотреть доклады в любое удобное для вас время. Кроме этого, в подарок вы получите запись прошедшей PPC Day!

Еще по теме:
- Ключевые слова для интернет-магазина: ориентиры при ручном подборе
- Два подхода к подбору семантического ядрa
- Как расширить семантическое ядро с помощью данных Я.Вебмастера и Google Search Console
- Как расширить семантическое ядро с помощью данных Яндекс.Метрики
- Семантическое ядро: как правильно подобрать ключевые фразы для продвижения сайта
Если вы только начинаете работать над своим интернет-магазином или хотите пересмотреть подобранное семантическое ядро, эта статья будет вам полезна. Мы расписали, на что нужно ориентироваться при ручном…
Владельцам коммерческих ресурсов, чтобы улучшить видимость своего сайта в поиске и увеличить посещаемость, нужно работать с широким списком ключевых запросов. Как это сделать? Мы рассмотрим…
Улучшить поисковую видимость сайта можно не только созданием новых посадочных страниц, но и доработкой уже созданных и оптимизированных. Сегодня мы хотим поделиться простым и эффективным…
Как улучшить уже существующее семантическое ядро? В статье мы рассказываем, как расширить семантику, использовав данные своего сайта в Яндекс.Метрике. Пошаговая инструкция и советы, которые смогут…
Подбор ключевых фраз – очень важный этап в продвижении сайта. В данной статье мы осветим важные моменты, которые помогут составить семантическое ядро вашего сайта так,…

SEO-аналитик
Работу в сфере IT начинал с должности контент-менеджера. Уже при создании своих личных проектов постепенно узнавал, что такое SEO, увлекло. Вдохновляюсь сложными и интересными задачами.
Мои увлечения: велоспорт и книги.
Девиз: «Другой жизни не будет!»
Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.

Задача подобрать ключевые слова для SEO сайта или контекстной рекламы — это важнейший шаг, который может определить успех всей дальнейшей работы, будь то поисковое продвижение сайта или настройка контекстной рекламы. Как правильно собирать ключевые слова для рекламной кампании мы уже рассказывали. Сейчас мы рассмотрим составление семантического ядра для поискового продвижения сайта. На первый взгляд простая задача найти и собрать ключевые слова на самом деле имеет достаточно глубокий смысл. Нельзя просто так взять ключевые слова и сделать сайт.
Здесь я расскажу не о том, как пользоваться вордстатом или другими вундервафлями для сбора ключевых слов, а о том, зачем вообще собираются ключевые слова, создается семантическое ядро сайта и как это все влияет на ранжирование сайта в поиске.
Ключевые слова для SEO сайта
Ключевые слова или семантическое ядро сайта — это мозг сайта, и чем в нём больше логических связей, тем он «умнее». Проще говоря: если на сайте больше 10 страниц, то страницам сайта нужна логическая организация, иначе возникнет путаница в том, какая страница на какой ключевой запрос отвечает. Каждая страница сайта должна отвечать на определенный запрос, и только одна страница должна быть самой релевантной страницей по конкретному ключевому запросу. Не хватало еще, чтобы страницы сайта конкурировали друг с другом по одним и тем же ключевым словам.
Возьмем тему, например, мы хотим продавать ложки. Мы ищем все возможные ключевые слова про ложки и выделяем из них те, которые необходимы нам в первую очередь, чтобы наши ложки продать. В результате, ключевые слова делятся на две большие группы: тематические ключевые слова, в которые входят торговые запросы, товарные категории, запросы по товарной базе и информационные запросы по теме. Как правило, информационных запросов во много раз больше, чем тематических торговых запросов, однако, именно информационные запросы позволяют описать логику тематики, чтобы продвинуть сайт по торговым запросам.
Более того, одних ключевых слов по теме «ложки» недостаточно, чтобы исчерпывающе дать определение всей тематике ложек, т. к. тематика «ложки» является частью более объемной тематики «столовые приборы» и имеет прямые связи с такими темами, как «вилки» и «ножи». То есть именно в контексте темы «столовые приборы» раскрывается логика темы «ложки». В данном случае, темы «вилки» и «ножи» могут быть смежными запросами ключевым словам по теме «ложки».
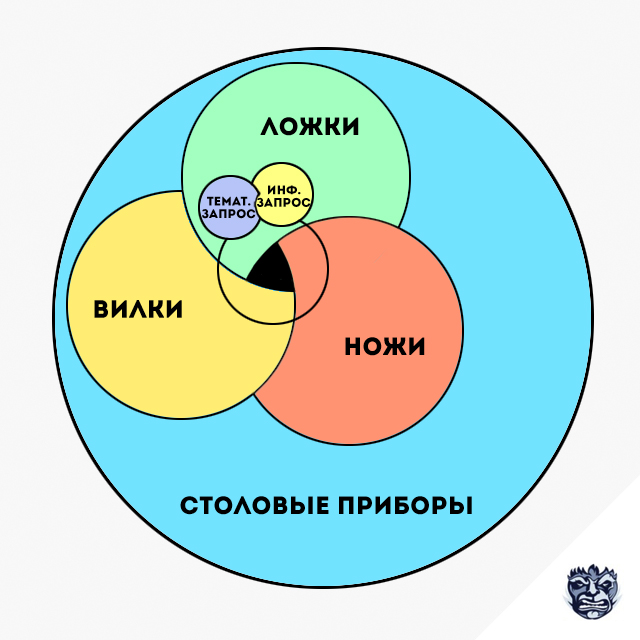
Рис. 1. Чтобы полноценно описать тему «ложки» необходимо частично описать тему «вилки», «ножи» и другие аспекты глобальной темы «столовые приборы».
Замыкаем логику тематики через смежные ключевые запросы
Чтобы заниматься полноценным SEO своего сайта, необходимо усвоить основной принцип: четкая логическая структура всех страниц сайта — это основа поисковой оптимизации. Без жесткого распределения ключевых запросов по страницам и организации связей между страницами вы не сможете объяснить ни людям, ни поисковым системам, где находится та или иная информация на вашем сайте. Без этого оптимизация сайта невозможна. Точность разграничения и полнота охвата тематики играет важную роль в определении релевантности каждой страницы по соответствующему ключевому слову.
Определенная тематика описывается про помощи ключевых слов, характерных для этой тематики, а так же при помощи ключевых слов, позволяющих описать место более узкой тематики в рамках более широкой. Возвращаясь к примеру выше, тематики «вилки» и «ножи» описывают место узкой тематики «ложки» в рамках более широкой тематики «столовые приборы». Все ключевые слова имеют логические связи с другими ключевыми словами как в рамках одной темы, так и с ключевыми словами других тематик разной степени близости.
Ключевые слова близких по смыслу тематик называются смежные запросы. В том же Яндексе, подбор слов позволяет узнать, что еще искали посетители Яндекса, кроме определенного запроса. В случае с нашей темой, с ложками ищут вилки, ножи и, например, тарелки или салфетки. То есть в данном случае, при необходимости охвата тематики «столовые приборы», смежные запросы помогут найти все более узкие тематики. Что касается сервиса wordstat.yandex.ru, то с его помощью можно получить замкнутую последовательность ключевых слов и тематик. Достаточно ввести ключевое слово и следовать по смежным запросам до тех пор, пока в смежных запросах не окажется изначальный запрос. Это особенно важно при описании обширных, нечетких тематик, которые сложно, а порой и вовсе невозможно, описать или выразить в виде ключевого слова или фразы.
Ищем логические синонимы
Кроме смежных запросов и тематик, огромное значение в сборе ключевых слов играют синонимы ключевых запросов. Синонимом ключевого слова «лендинг» может быть landing page или посадочная страница. Все три слова в разной степени востребованности означают одно и то же понятие. Кроме явных синонимов, часто встречаются различные формулировки ключевых запросов или фраз, т. е. логические синонимы. Зачастую, одно и то же понятие можно описать по-разному, что существенно расширяет список потенциальных ключевых слов. Поисковые системы вычисляют логическую связь между синонимами, и релевантнее может оказаться та страница, которая использует все разнообразные формулировки одно ключевого запроса, нежели страница с одной единственной формулировкой ключевого слова.
Собираем минус слова
При подборе ключевых слов необходимо ориентироваться на реальную статистику ключевых слов, которую предоставляют поисковые системы. Сторонние программы, которые собирают ключевые слова на основе собственных внутренних ресурсов не отражают реальную картину запросов пользователей поисковых систем. Поэтому берите ключевые слова и статистику непосредственно из поисковых систем, а не из сторонних ресурсов, которые предоставляют информацию на основании собственных представлений, а не реальных данных из Яндекса или Google. Таким образом, вы изначально не будете забивать себе голову тем, что вам по определению не нужно. А дальше можно начинать фильтровать реальные данные.
Минус слова позволяют исключить ключевые слова, которые однозначно не имеют отношения к специфики вашего сайта. Список ключевых слов, которые нужно отминусовать, может быть огромен, но чем точнее определена тематика, тем проще будет создать логическую структуру сайта. Тем более, что в статистике ключевых слов встречаются как откровенно бредовые запросы, так и запросы, которые могут удовлетворять смыслу сторонних тематик, даже близко не связанных с вашей. Из-за подобных особенностей русского языка, подбор минус слов часто становится достаточно трудоемким процессом, к которому нужно отнестись с особым вниманием.
Собираем все до последнего ключевого слова
При составлении семантического ядра нередко количество ключевых слов ограничивается из-за непопулярности некоторых низкочастотных слов. Происходит это по принципу: зачем мне ключевые слова, которые имеют меньше 100, 50 или 10 запросов в месяц или очень низкочастотные запросы. Все дело в том, что не все понимают, как накапливается статистика запросов ключевых слов и что вообще такое низкочастотные слова. Если коротко, то низкочастотные запросы — это запросы, которые состоят из нескольких слов и имеют очень точную формулировку, например: «купить iPhone 5C 16gb желтый с зеленым чехлом в Москве б/у».
Действительно, именно такой запрос может быть один в месяц, но в целом подобных низкочастотных запросов могут быть тысячи. Но самое главное, эти запросы имеют низкую конкуренцию и очень высокую конверсию, так как в данных запросах люди выражают конкретную потребность, а не абстрактное желание ознакомиться с тем, что такое «iPhone 5C». Подумайте, что для вас проще:
- вывести сайт по 1000 высокоточных низкочастотных запросов, в которых нет конкуренции и получать трафик и заказы сразу, как только страница сайта попадет в поиск;
- вывести сайт по 10 абстрактным ключевым запросам с большой конкуренцией, где большую часть трафика составляют люди, которые ищут информацию, конкуренты или боты.
Безусловно, все зависит от тематики, ресурсов и времени. В итоге решать вам, но тот кто забывает или пренебрегает низкочастотными ключевыми словами, в буквальном смысле, не видит денег у себя под ногами. Поэтому, собирайте все до последнего ключевого слова, даже если у него по статистике всего 1 показ в месяц.
Группируем ключевые запросы
Организация страниц и ключевых слов невозможна без группировка ключевых слов. Группировать ключевые слова можно по частоте, как минимум, на высокочастотные, среднечастотные и низкочастотные. Вообще, группировка ключевых слов должна идти от большего к меньшему, вплоть до отдельных ключевых запросов. В зависимости от группировки ключевых слов могут получиться целые разделы и подразделы сайта, а из некоторых групп ключевых слов может получиться отдельная страница. Например, почему бы не собрать список ключевых слов по какому-нибудь интересному определению в узкой теме, чтобы написать об этом определении статью. Собираем ключевые слова, группируем их по смыслу и получаем готовое содержание статьи, которое даст ответы на 100% запросов, которые были заданы в поиске. Плюс к релевантности.
Итог
- Подбирайте ключевые слова только на основании статистики самих поисковых систем или через сервисы, которые работают непосредственно со статистикой поисковых систем, а не высасывают собственную статистику и ключи из пальца.
- Собирайте все возможные ключевые слова и не пренебрегайте низкочастотными ключевыми словами, мало ключей не бывает.
- Очень внимательно фильтруйте ключевые слова, так как бесполезный трафик не даст вам ничего, кроме траты времени и большого числа отказов на сайте.
- Группируйте ключевые слова, чтобы четче разделять логику связей групп страниц и разделов.
- Продумайте логическую структуру всех страниц сайта и определите каждой странице свое место и свой ключевой запрос, уникальный по смыслу и содержанию страницы.
Каждая страница сайта должна отвечать на свой вопрос. Один вопрос — одна страница. Подбирайте ключевые слова так, чтобы они четко укладывались в тот вопрос, которому посвящена страница сайта. Связывайте страницы ссылками, когда это необходимо по смыслу, чтобы создать логическую связь между страницами. И самое главное — постарайтесь описать свою тематику максимально полно, и тогда — победа!
Пишите в комментариях свое мнение и делитесь постом с друзьями.
Больше вашей активности — больше интересных статей.
Часто начинающие вебмастера, сталкиваясь с необходимостью создания семантического ядра, не знают с чего начать. Хотя ничего сложного в этом процессе нет. Проще говоря, нужно собрать список ключевых фраз по которым интернет пользователи ищут информацию, находящуюся на вашем сайте.
Чем полнее и точнее он будет, тем проще копирайтеру написать хороший текст, а вам получить высокие позиции в поиске по нужным запросам. О том, как правильно составлять большие и качественные смысловые ядра и что с ними делать дальше, чтобы сайт выходил в топ и собирал много трафика, и пойдёт речь в этом материале.
Что из себя представляет ядро сайта?
Семантическое ядро — это набор ключевых фраз, разгруппированных по смыслу, где каждая группа отражает одну потребность или желание пользователя (интент). То есть то, о чем думает человек, вбивая свой запрос в поисковую строку.
Весь процесс создания ядра можно представить в 4 шагах:
- Сталкиваемся с задачей или проблемой;
- В голове формулируем, как можно найти её решение через поиск;
- Вбиваем запрос в Яндекс или Гугл. Помимо нас, то же самое делают и другие люди;
- Наиболее частые варианты обращений попадают в сервисы аналитики и становятся ключевыми фразами, которые мы с вами собираем и группируем по потребностям. В результате всех этих манипуляций получается семантическое ядро.
Обязательно ли подбирать ключевые фразы или можно обойтись без этого?
Раньше семантику составляли для того, чтобы найти наиболее частотные ключевики по теме, вписать их в текст и получить хорошую видимость по ним в поиске. Последние 5 лет поисковые системы стремятся перейти на модель, где релевантность документа запросу будет оцениваться не по количеству слов и разнообразию их вариаций в тексте, а по оценке раскрытия интента.
У Гугл — это началось в 2013 году с алгоритмом Колибри, у Яндекса в 2016 и 2017 с технологиями Палех и Королев соответственно.
Тексты, написанные без СЯ, не смогут полностью раскрыть тему, а значит конкурировать с ТОП-ом по высокочастотным и среднечастотным запросам не получится. Делать ставку на низкочастотные запросы не имеет смысла — слишком мало трафика по ним.
Если вы хотите и в будущем успешно продвигать себя или свой продукт в интернете — нужно научиться составлять правильную семантику, которая полностью раскрывает потребности пользователей.
Классификация поисковых запросов
Разберем 3 типа параметров, по которым оцениваются ключевые слова.
По частотности:
- Высокочастотные (ВЧ) – фразы, определяющие тему. Состоят из 1-2 слов. В среднем количество поисковых запросов начинается от 1000-3000 в месяц и может достигать сотен тысяч показов, зависит от тематики. Чаще всего под них затачиваются главные страницы сайтов.
- Среднечастотные (СЧ) – отдельные направления в теме. Преимущественно содержат 2-3 слова. С точной частотностью от 500 до 1000. Обычно категории коммерческого сайта или темы для крупных информационных статей.
- Низкочастотные (НЧ) – запросы, относящиеся к поиску конкретного ответа на вопрос. Как правило, от 3-4 слов. Это может быть карточка товара или тема статьи. В среднем ищут от 50 до 500 человек в месяц.
- При анализе метрики или данных счетчиков статистики можно встретить еще один вид — микро НЧ ключи. Это фразы, которые часто спрашивают единожды на поиске. Смысла затачивать под них страницу нет. Достаточно быть в топе по НЧ, который в себя их включает.
По конкурентности:
- Высоконкурентные (ВК);
- Среднеконкрентые (СК);
- Низконкурентные (НК);
По потребности:
- Навигационные. Выражают желание пользователя найти конкретный интернет-ресурс или информацию на нем;
- Информационные. Характеризуются наличием потребности в получении информации в качестве ответа на запрос;
- Транзакционные. Напрямую связаны с желанием совершить покупку;
- Нечеткие или общие. Те по которым сложно точно определить интент.
- Геозависимые и геонезависимые. Отражают потребность в поиске информации или совершения транзакции в своем городе или без региональной привязки.
В зависимости от типа сайта можно дать следующие рекомендации при подборе ключевых фраз для семантического ядра.
- Информационный ресурс. Основной упор стоит сделать на поиске тем для статей в виде СЧ и НЧ запросов с низкой конкуренцией. Рекомендуется раскрывать тему широко и глубоко, затачивая страницу под большое количество НЧ ключей.
- Интернет-магазин или коммерческий сайт. Собираем ВЧ, СЧ и НЧ, максимально четко сегментируя, чтобы все фразы были транзакционного типа и относились к одному кластеру. Акцент делаем на поиск хорошо конвертируемых НЧ НК ключевиков.
Как правильно составить большое смысловое ядро – пошаговая инструкция
Мы перешли к главной части статьи, где я буду последовательно, разбирать основные этапы, которые нужно пройти для построения ядра будущего сайта. Чтобы процесс был понятнее, все шаги даны с примерами.
Поиск основных фраз
Работа с сео ядром начинается с выбора первичного списка основных слов и словосочетаний (ВЧ), которые лучше всего характеризуют тематику и употребляются в широком смысле. Их еще называют маркерами.
Это могут быть, как названия направлений, так и виды продукции, популярные запросы из темы. Как правило они состоят из 1-2 слов и насчитывают десятки, а иногда и сотни тысяч показов в месяц. Совсем широкие ключи лучше не брать, чтобы не утонуть в минус-словах на этапе расширения.
Удобней всего подбирать маркерные фразы, используя Яндекс Вордстат. Вбивая запрос в него, в левой колонке мы видим словосочетания, которые он в себе содержит, в правой – похожие запросы из которых часто можно найти подходящие для расширения темы. Также сервис показывает базовую частотность фразы, то есть сколько раз ее спрашивали за месяц во всех словоформах и с добавлением любых слов к ней.
Сама по себе такая частотность мало интересна, поэтому чтобы получить более точные значения нужно использовать операторы. Разберем, что это такое и для чего нужно.
Операторы Яндекс Вордстат:
1) «…» – кавычки. Запрос в кавычках позволяет отследить сколько раз в Яндексе искали фразу со всеми ее словоформами, но без добавления других слов (хвостов).
2) ! – восклицательный знак. Используя его перед каждым словом в запросе мы фиксируем его форму и получаем количество показов в поиске по ключевой фразе только в указанной словоформе, но с хвостом.
3) «!… !… !…» – кавычки и восклицательный знак перед каждым словом. Самый важный оператор для оптимизатора. Он позволяет понять сколько раз ключевик запрашивают в месяц строго по заданному словосочетанию, в том виде как оно написано, без добавления каких-либо слов.
4) +. Яндекс Вордстат не учитывает предлоги и местоимения при запросе. Если нужно чтобы он их показал — ставим перед ними знак плюс.
5) -. Второй по важности оператор. С его помощью быстро отсеиваются слова, которые не подходят. Чтобы его применить после анализируемой фразы ставим минус и стоп-слово. Если их несколько повторяем процедуру.
6) (…|…). Если нужно получить от Яндекс Вордстат данные по нескольким фразам одновременно заключаем их в скобки и разделяем прямым слешом. На практике метод используется редко.
Для удобства работы с сервисом, рекомендую поставить специальное расширение для браузера «Wordstat Assistant». Ставится на Мозилу, Гугл Хром, Я.Браузер и позволяет копировать фразы и их частотности одним нажатием иконки «+» или «Добавить все».
Допустим мы решили сделать свой блог по сео. Выберем для него 7 основных фраз:
- семантическое ядро;
- оптимизация;
- копирайтинг;
- продвижение;
- сео;
- монетизация;
- Директ
Далее на примере ВЧ фразы «семантическое ядро» разберем пошагово, как строится весь процесс составления списка фраз. По остальным темам все делается точно также по аналогии.
Поиск синонимов
При формулировке запроса поисковым системам, пользователи могут использовать слова близкие по смыслу, но разные по написанию.
Например, «автомобиль» и «машина».
Важно найти, как можно больше синонимов к основным словам, чтобы увеличить охват будущего смыслового ядра. Если это не сделать, то при парсинге мы упустим целый пласт ключевых фраз, раскрывающих потребности пользователей.
Что используем:
- Мозговой штурм;
- Правую колонку Яндекс Вордстат;
- Запросы набранные на кириллице;
- Специальные термины, аббревиатуры, сленговые выражения из тематики;
- Блоки Яндекс и Гугл – вместе с «название запроса» ищут ;
- Сниппеты конкурентов.
В результате всех действий для выбранной темы получаем такой список фраз:
Расширение основных запросов
Распарсим эти ключевые слова, чтобы выявить основные потребности людей в этой сфере. Удобней всего это делать в программе Key Collector, но если жалко платить 1800 рублей за лицензию, пользуйтесь ее бесплатным аналогом — Словоёбом.
По функционалу он конечно слабее, но для небольших проектов подойдет. Если не хочется вникать в работу программ можно использовать сервис Just-Magiс и Rush Analytics. Но все-таки лучше потратить немного времени и разобраться с софтом.
Я буду показывать принцип работы в Кей Коллекторе, но если вы работаете со Словоебом, то тоже все будет понятно. Интерфейс программ схож.
Порядок действий:
1) Добавим список основных фраз в программу и снимем по ним базовую и точную частотность. Если мы планируем продвижение в конкретном регионе — указываем региональность. Для информационных сайтов чаще всего это не нужно.
2) Спарсим левую колонку Яндекс Вордстат по добавленным словам, чтобы получить все запросы из нашей темы.
3) На выходе у нас получилось 3374 фразы. Снимем по ним точную частотность, как в 1-ом пункте.
4) Проверим нет ли в списке ключей с нулевой базовой частотностью.
Если есть удаляем и переходим к следующему шагу.
Минус-слова
Многие пренебрегают процедурой сбора минус-слов, заменяя ее удалением фраз, которые не подходят. Но позже вы поймете, что это удобно и реально экономит время.
Открываем в Кей Коллекторе вкладку Данные -> Анализ. Выбираем тип группировки по отдельным словам и листаем список ключей. Если видим фразу, которая не подходит — нажимаем синюю иконку и добавляем слово вместо со всеми его словоформами в стоп-слова.
В Словоебе работа со стоп-словами реализовано в более упрощенном варианте, но вы также можете составить свой список фраз, которые не подходят и применять их к списку.
Не забываем использовать сортировку по Базовой частотности и количеству фраз. Эта опция помогает быстро уменьшить список исходных фраз или отсеять редко встречающиеся.
После того как мы составили список стоп-слов, применяем их к нашему проекту и переходим к сбору поисковых подсказок.
Парсинг подсказок
При вводе запроса в Яндекс или Гугл, поисковики предлагают свои варианты его продолжения из наиболее популярных фраз, которые вбивают пользователи интернета. Эти ключевики называются поисковыми подсказками.
Многие из них не попадают в Вордстат, поэтому при построении семантического нужно обязательно собирать такие запросы.
Кей Коллектор, по умолчанию парсит их с перебором окончаний, кириллического и латинского алфавита и с пробелом после каждого словосочетания. Если вы готовы готовы пожертвовать количеством, чтобы значительно ускорить процесс, ставим галочку на пункте «Собирать только ТОП подсказок без перебора и пробела после фразы».
Часто среди поисковых подсказок можно найти фразы с хорошей частотностью и конкуренцией в десятки раз ниже, чем в Вордстате, поэтому в узких нишах я рекомендую собирать максимум слов.
Время парсинга подсказок напрямую зависит от количество одновременных обращений к серверам поисковым систем. Максимально Кей Коллектор поддерживает 50-ти поточную работу. Но для того чтобы парсить запросы в таком режиме понадобится столько же прокси и аккаунтов в Яндексе.
Для нашего проекта, после сбора подсказок, получилось 29595 уникальных фраз. По времени весь процесс занял чуть больше 2-х часов на 10 потоках. То есть, если их будет 50 — уложимся в 25 минут.
Определение базовой и точной частотности для всех фраз
Для дальнейшей работы важно определить базовую и точную частотность и отсеять все нулевики. Запросы с малым количеством показов оставляем, если они целевые. Это поможет лучше понять интент и создать более полную структуру статьи, чем есть в топе.
Для того, чтобы снять частотность сначала отсеиваем все лишнее:
- повторы слов
- ключи с прочими символами;
- дубли фраз (через инструмент «Анализ неявных дублей»)
Для оставшихся фраз определим точную и базовую частотность.
а) для фраз до 7 слов:
- Выбираем через фильтр «Фраза состоит не более чем из 7 слов»
- Открываем окошко «Сбор с Yandex.Direct», кликнув по иконке «Д»;
- Если нужно указываем регион;
- Выбираем режим гарантированные показы;
- Ставим период сбора – 1 месяц и галочки над нужными видами частотностей;
- Нажимаем «Получить данные».
б) для фраз от 8 слов:
- Задаем для графы «Фраза» фильтр — «состоит, как минимумом из 8 слов»;
- При необходимости продвижения в конкретном городе внизу указываем регион;
- Нажимаем на лупу и выбираем «Собрать все виды частот».
Чистка ключевых слов от мусора
После того, как мы получили информацию о количестве показов для наших ключей можно приступать к отсеву не подходящих.
Рассмотрим порядок действий по шагам:
1. Переходим в «Анализ групп» Кей Коллектора и сортируем ключи по количеству употребления слов. Задача найти нецелевые и частые и занести их в список стоп-слов. Делаем все также как в пункте «Минус слова».
2. Применяем к списку наших фраз все найденные стоп-слова и пробегаемся по нему, чтобы точно не потерять целевые запросы. После проверки нажимаем удалить «Отмеченные фразы».
3. Отсеиваем фразы пустышки, которые редко используются в точном вхождении, но имеют высокую базовую частоту. Для этого в настройках программы Кей Коллектор в пункте «KEY&SERP» вставляем формулу расчета: KEY 1 = ( YandexWordstatBaseFreq ) / ( YandexWordstatQuotePointFreq ) и сохраняем изменения.
4. Производим расчет KEY 1 и удаляем те фразы у которых этот параметр получился от 100 и больше.
Оставшиеся ключи нужно сгруппировать по посадочным страницам.
Кластеризация
Распределение запросов по группам начинается с кластеризации фраз по топу через бесплатную программу «Majento Кластеризатор». Я рекомендую, платный аналог с более широким функционалом и быстрой скоростью работы — KeyAssort, но и бесплатного вполне хватает для небольшого ядра. Единственный нюанс, что для работы в любом из них нужно будет купить XML-лимиты. Средняя цена – 5 р. за 1000 запросов. То есть обработка среднего ядра на 20-30 тысяч ключей обойдется в 100-150 р. Адрес сервиса, которым пользуясь, смотрите на скриншоте ниже.
Суть кластеризации ключей этим методом заключается в объединении в группы тех фраз, которые имеют по Топ-10 Яндекса:
- общие url-ы друг с другом (Hard)
- с самым частотным запросом в группе (Soft).
В зависимости от количества таких совпадении для разных сайтов, выделяют пороги кластеризации: 2, 3, 4 … 10.
Преимущество способа – группировка словосочетаний по потребностям людей, а не только по синонимическим связям. Это позволяет сразу понять какие ключевики можно использовать на одной посадочной странице.
Для информационников подойдет:
- Soft с порогом 3-4 и потом чистка руками;
- Hard на 3-ке, а потом объединение кластеров по смыслу.
Интернет-магазины и коммерческие сайты, как правило, продвигается по Hard-у с порогом кластеризации 3.Тема объемная, поэтому я позже разберу ее в отдельной статье.
Для нашего проекта после группировки методом Hard на 3-ке получилось 317 групп.
Проверка конкуренции
Нет смысла продвигаться по высококонкурентным запросам. В топ попасть сложно, а без него трафика на статью не будет. Чтобы понять на какие темы выгодно писать используем следующий метод:
Ориентируемся на точную частотность группы фраз под которую пишется статья и конкуренцию по Мутагену. Для информационных сайтов, я рекомендую, брать в работу темы, у которых суммарная точная частотность от 300 и выше, а коэффицент конкурентности от 1 до 12 включительно.
В коммерческой тематике ориентируйтесь на маржинальность товара или услуги и то как делают конкуренты в топ 10. Даже 5-10 целевых запросов в месяц может быть основанием сделать под нее отдельную страницу.
Как проверить конкуренцию по запросу:
а) вручную, вбив соответствующую фразу в самом сервисе или через массовые задания;
б) в пакетном режиме через программу Кей Коллектор.
Выбор тем и группировка
Рассмотрим, каждую из получившихся групп для нашего проекта после кластеризации и выберем темы для сайта. Majento в отличии от Key Assort не дает возможность загрузить данные о количестве показов для каждой фразы, поэтому придется дополнительно снимать их через Кей Коллектор.
Инструкция:
1) Выгружаем все группы из Majento в формате CSV; 2) Сцепляем фразы в Excel по маске «группа:ключ»; 3) Загружаем полученный список в Key Сollector. В настройках обязательно должна стоять галочка в режиме импортирования «Группа:Ключ» и не следить за наличием фраз в других группах;
4) Снимаем для ключевиков из вновь созданных групп базовую и точную частотность. (Если вы пользуетесь Key Assort, то это делать не нужно. Программа позволяет работать с дополнительными столбцами) 5) Ищем кластеры с уникальным интентом, содержащие не менее 3-х фраз и количеством показов по всем запросам в сумме больше 300. Далее проверяем 3-4 самые частотные из них на конкурентность по Мутагену. Если среди этих словосочетаний есть ключи с конкуренцией меньше 12 — берем в работу;
6) Просматриваем остальные группы. Если встречаются близкие по смыслу словосочетания и их стоит рассмотреть в рамках одной страницы — объединяем. Для групп, содержащих новые смыслы смотрим на перспективы по суммарной частотности фраз, если она меньше 150 в месяц, то откладываем до того момента, как пройдемся по всему ядру. Возможно получится их объединить с другим кластером и набрать 300 точных показов — это тот минимум от которого стоит брать статью в работу. Для ускорения ручной группировки пользуйтесь вспомогательными инструментами: быстрый фильтр и частотный словарь. Они помогут быстро найти подходящие фразы из других кластеров;
Внимание!!! Как понять, что кластера можно объединить? Берем 2 частотных ключа из тех что подобрали в пункте 5 для посадочной страницы и 1 запрос из новой группы. Добавляем их в инструмент Арсенкина «Выгрузка Топ 10», указываем нужный регион при необходимости. Далее смотрим на количество пересечений по цвету для 3-ой фразы с остальными. Объединяем группы, если их от 3-х и более. Если нет совпадений или одно, объединять нельзя — разные интенты, в случае с 2-мя пересечениями смотрите выдачу руками и используйте логику.
7) После группировки ключей получаем список перспективных тем для статей и семантику под них.
Удаление запросов другого типа контента
При составлении семантического ядра важно понимать, что для блогов и информационных сайтов коммерческие запросы не нужны. Так же, как и интернет-магазинам не нужна информационка.
Пробегаемся по каждой группе и чистим все лишнее, если не получается точно определить интент запроса — сравниваем выдачу или используем инструменты:
- Проверку на коммерциализацию от Пиксель Тулс (бесплатно, но с дневным лимитом проверок);
- сервис Just-Magic, кластеризация с галочкой проверить коммерческость запроса (платно, стоимость зависит от тарифа)
После этого переходим к последнему этапу.
Оптимизация фраз
Оптимизируем смысловое ядро, чтобы с ним было удобно работать в дальнейшем seo-специалисту и копирайтеру. Для этого оставим в каждой группе ключевые фразы, которые максимально полно отражают потребности людей и содержат, как можно больше синонимов к основным фразам.
Алгоритм действий:
- Отсортируем ключевики в Excel или Кей Коллектор по алфавиту от А до Я;
- Выберем те, которые раскрывают тему с разных сторон и разными словами. При прочих равных оставляем фразы с более высокой точной частотностью или у которых ниже показатель key 1 (отношение базовой частоты к точной);
- Удаляем ключевики с количеством показов в месяц меньше 7, которые не несут новых смыслов и не содержат уникальных синонимов.
Пример, как выглядит грамотно составленное смысловое ядро – Скачать
Красным цветом я отметил фразы не подходящие по интенту. Если пренебречь моими рекомендациями по ручной группировке и не проверять совместимость получится, что страница будет оптимизирована под несовместимые ключевые фразы и высоких позиций по продвигаемым запросам уже не видать.
Итоговый чек-лист
- Подбираем основные высокочастотные запросы, которые задают тематику;
- Ищем синонимы к ним, используя левую и правую колонку Вордстат, сайты конкурентов и их сниппеты;
- Расширяем полученные запросы парсингом левой колонки Вордстат;
- Готовим список стоп-слов и применяем к полученным фразам;
- Парсим подсказки Яндекс и Гугл;
- Снимаем базовую и точную частотку;
- Расширяем список минус-слов. Чистим от мусора и запросов пустышек
- Делаем кластеризацию через Majento или KeyAssort. Для информационных сайтов в режиме Soft, порог 3-4. Для коммерческих интернет-ресурсов методом Hard с порогом 3.
- Импортируем данные в Кей Коллектор и определяем конкуренцию 3-4 фраз для каждого кластера с уникальным интентом;
- Выбираем темы и определяемся с посадочными страницами под запросы на основе оценки суммарного количество точных показов по всем фразам из одного кластера (от 300 для информационников) и конкуренции по самым частотным из них по Мутагену (до 12).
- Для каждой подходящей страницы ищем другие кластеры с похожими потребностями пользователей. Если мы можем их рассмотреть на одной странице – объединяем. Когда потребность не ясна или есть подозрения, что в качестве ответа на нее должен быть другой тип контента или страницы — проверяем по выдаче или через инструменты Пиксель Тулс или Just-Magic. Для контентных сайтов ядро должно состоять из информационных запросов, у коммерческих из транзакционных. Лишнее удаляем.
- Сортируем ключи в каждой группе по алфавиту и оставляем те из них, которые описывают тему с разных сторон и разными словами. При прочих равных приоритет тем запросам, у которых меньше отношение базовой частотности к точной и более высокое количество точных показов в месяц.
Что делать с SEO-ядром после его создания
Составили список ключей, отдали их автору и он написал отличную статью полностью, раскрывающую все смыслы. Эх, что то я размечтался… Толковый текст получится только в том случае, если копирайтер четко понимает, что вы от него хотите и как ему себя проверить. Разберем 4 составляющие, качественно проработав, которые вы гарантировано получите много целевого трафика на статью:
Хорошая структура. Анализируем запросы, подобранные для посадочной странице и выявляем, какие потребности есть у людей в этой теме. Далее пишем план статьи, который полностью отвечает на них. Задача сделать так, чтобы люди, зайдя на сайт получили объемный и исчерпывающий ответ по той семантике, которую вы составили. Это даст хорошие поведенческие и высокую релевантность интенту. После того как вы составили план, посмотрите сайты конкурентов, вбив основной продвигаемый запрос в поиск. Делать нужно именно, в такой последовательности. То есть сначала делаем сами, потом смотрим что у других и если нужно дорабатываем.
Оптимизация под ключи. Саму статью затачиваем под 1-2 самых частотных ключа с конкуренцией по Мутагену до 12. Еще 2-3 среднечастотные фразы можно использовать в качестве заголовков, но в разбавленном виде, то есть вставляя в них дополнительные не относящиеся к теме слова, используя синонимы и словоформы. Основной упор делаем на низкочастотные фразы из которых выдергивает уникальную часть — хвост и равномерно внедряем в текст. Поисковики сами все найдут и склеят.
Синонимы к основным запросам. Выписываем их отдельно из нашего семантического ядра и ставим задачу копирайтеру использовать их равномерно по тексту. Это поможет снизить плотность по нашим основным словам и при этом текст получится достаточно оптимизированным, чтобы попасть в топ.
Тематико-задающие фразы. Сами по себе LSI не продвигают страницу, но их наличие указывает на то, что скорее всего написанный текст принадлежит «перу» эксперта, а это уже плюс к качеству контента. Для поиска тематических словосочетаний используем инструмент «Техническое задание для копирайтера» от Пиксель Тулс.
Альтернативный метод подбора ключевых фраз с использованием сервисов для анализа конкурентов
Существует быстрый подход к созданию семантического ядра, который применим как для новичков, так и для опытных пользователей. Суть метода заключается в том, что мы изначально выбираем ключи не для всего сайта или категории, а конкретно под статью, посадочную страницу.
Его можно реализовать 2-мя способами, которые отличаются тем, как мы выбираем темы для страницы и насколько глубоко расширяем ключевые фразы:
- с помощью парсинга основных ключей;
- на основе анализа конкурентов.
Каждый из них можно реализовать на простом и более сложном уровне. Разберем все варианты.
Без использования программ
Копирайтеру или вебмастеру часто не хочется разбираться с интерфейсом большого количества программ, но нужны хорошие темы и ключевые фразы под них. Этот метод, как раз для новичков и тех кто не хочет заморачиваться. Все действия производятся без использования дополнительного софта, с помощью простых и понятных сервисов.
Что понадобится:
- Сервис Keys.so для анализа конкурентов – 1500 р. По промокоду «altblog» — скидка 15%;
- Мутаген. Проверка конкурентности запросов – 30 копеек, сбор базовой и точной частотности – 2 копейки за 1 проверку;
- Букварикс – бесплатная версия или бизнес-аккаунт — 995 р. (сейчас со скидкой 695 р)
Вариант 1. Выбор темы через парсинг основных фраз:
- Подбираем основные ключи из тематики в широком смысле, используя мозговой штурм и левую и правую колонку Яндекс Вордстат;
- Далее ищем к ним синонимы, методами о которых говорилось раннее;
- Забиваем все полученные маркерные запросы в Букварикс (понадобится оплатить платный тариф) в расширенном режиме «Поиск по списку ключевых слов»;
- Указываем в фильтре: «!Точная !частотность»от 50, Количество слов от 3;
- Выгружаем весь список в Excel;
- Выделяем все ключевики и отправляем на группировку в сервис «Кулаков кластеризатор». Если сайт региональный выбираем нужный город. Порог кластеризации для информационных сайтов оставляем на 2-х, для коммерческих ставим 3-ку;
- После группировки выбираем темы для статей, просматривая получившиеся кластеры. Берем те, где количество фраз от 3-х и с уникальным интентом. Лучше понять потребности людей помогает анализ url-ов сайтов из топа в графе «Конкуренты» (справа в табличке сервиса Кулакова). Также не забываем проверять конкурентность по Мутагену. Пробиваем 2-3 запроса из кластера. Если все больше 12, то тему брать не стоит;
- С названием будущей посадочной страницы определились, осталось подобрать ключевые фразы для нее;
- Из поля «Конкуренты» копируем 3 урла с подходящим типом страниц (если сайт информационный – берем ссылки на статьи, если коммерческий, то на магазины);
- Вставляем их последовательно в keys.so и выгружаем все ключевые фразы по ним;
- Объединяем их в Excel-е и удаляем дубли;
- Данных только сервиса недостаточно, поэтому надо расширить их. Снова воспользуемся Буквариксом;
- Полученный список отправляем на кластеризации в «Кулаков кластеризатор»;
- Отбираем группы запросов, которые подходят для посадочной страницы, ориентируясь на интент;
- Снимаем базовую и точную частотность через Мутаген в режиме «Массовые задания»;
- Выгружаем список с уточненными данными по количеству показов в Excel. Удаляем нулевки для обоих видов частоток;
- Также в Excel, добавляем формулу отношения базовой частотности к точной и оставляем только те ключи у которых это отношение меньше 100;
- Удаляем запросы другого типа контента;
- Оставляем фразы, которые максимально полно и разными словами раскрывают основной интент;
- Повторяем все те же действия по пунктам 8-19 для остальных тем.
Вариант 2. Выбираем тему через анализ конкурентов:
1. Ищем топовые сайты в нашей тематике, вбивая ВЧ запросы и просматривая выдачу через инструмент Арсенкина «Анализ Топ-10». Достаточно найти 1-2 подходящих ресурса. Если продвигаем сайт в конкретном городе указываем региональность; 2. Переходим в сервис keys.so и вводим в него url-ы сайтов, которые нашли и смотрим какие страницы конкурентов приносят больше всего трафика. 3. 3-5 самых точных частотных запроса из них проверяем на конкурентность. Если по всем фразам она выше 12, то лучше поискать другую тему менее конкурентную. 4. Если нужно найти больше сайтов для анализа открываем вкладку «Конкуренты» и задаем параметры: похожесть — 3, тематичность — 10. Сортируем данные по убывания трафика. 5. После того как мы выбрали тему, вбиваем ее название в выдачу и копируем 3 урла из топа. 6. Далее повторяем пункты 10-19 из 1-го варианта.
С использованием Кей Коллектора или Словоеба
Этот метод будет отличаться от предыдущего только использованием для некоторых операции программы Кей Коллектор и более глубоким расширением ключей.
Что понадобится:
- программа Кей Коллектор – 1800 рублей;
- все те же сервисы, что и в предыдущем способе.
«Продвинутый – 1»
Пункты 1-14 совпадают с вариантом 1. Далее производим следующие действия:
- Парсим левую и правую колонку Яндекса по всему списку фраз;
- Снимаем точную и базовую частотность через Кей Коллектор;
- Вычисляем показатель key 1;
- Удаляем запросы нулевки и с key 1 > 100;
- Далее делаем все также, как в пунктах 18-19 варианта 1.
«Продвинутый — 2»
- Делаем шаги 1-5, как в варианте 2;
- Собираем по каждому url-у ключи в keys.so;
- Удаляем дубли в Кей Коллекторе;
- Повторяем Пункты 1-4, как в методе «Продвинутый -1».
Теперь сравним количество полученных ключей и их точную суммарную частотность при сборе СЯ разными методами:
МетодыОбщая частотностьТочная частотностьКоличество фразА) Классический метод. Подбираем ключевики сразу по всему ядру (посмотреть)
2161
760
39
Б) Под статью с помощью сервисов анализа конкурентов keys.so + Букварикс (посмотреть)
1874
708
29
В) Под статью. «Продвинутый метод 1,2». Те же сервисы + парсинг Кей Коллектором левой колонки Вордстат + Яндекс подсказки (посмотреть)
2838
1149
52
Как видим из таблицы, лучший результат показал альтернативный метод создания ядра под страницу — «Продвинутый 1,2». Удалось получить на 34% больше целевых ключей и при этом суммарный трафик по кластеру получился на 51% больше, чем в случае с классическим методом.
Ниже на скриншотах, видно, как выглядит готовое ядро, в каждом из случаев. Я взял фразы с точным количеством показов от 7 в месяц, чтобы можно было оценить качество ключевиков. Полную семантику смотрите в таблице по ссылке «Посмотреть».
А) Б) В)
Теперь вы знаете, что не всегда самый распространенный способ, как делают все, самый верный и правильный, но отказываться от других методов тоже не стоит. Многое зависит от самой тематики. Для коммерческих сайтов, где ключей не так много, вполне достаточно и классического варианта. На информационных сайтах также можно получить отличные результаты, если правильно составить ТЗ копирайтеру, сделать хорошую структуру и seo-оптимизацию. Обо всем этом мы подробно поговорим в следующих статьях.
В своей группе вк я добавил лайфхак, как выйти в топ даже со слабенькой семантикой. Подписывайтесь, чтобы не пропустить много полезных материалов и seo-фишек, которые я использую в своих проектах.
3 частые ошибки при создании семантического ядра
1. Сбор фраз по верхам. Недостаточно спарсить Вордстат, чтобы получить хороший результат! Более 70% запросов, которые вводят люди редко или периодами, вообще туда не попадают. А ведь среди них часто встречаются ключевые фразы с хорошей конверсией и реально низкой конкуренцией. Как их не упустить? Обязательно собирайте поисковые подсказки и комбинируйте их с данными из разных источников (Яндекс Метрика, счетчики на сайтах, сервисы статистики и базы данных).
2. Смешивание информационных и коммерческих запросов на одной странице. Мы уже разбирали, что ключевые фразы различаются по типу потребностей. Если к вам на сайт приходит посетитель, который хочет совершить покупку, а видит в качестве ответа на свой запрос страницу со статьей, как вы думаете будет ли он удовлетворен? Нет! Также думают и поисковые системы, когда ранжируют страницу, а значит про топ по СЧ и ВЧ фразам можно сразу забыть. Поэтому, если вы сомневаетесь в определении типа запроса смотрите выдачу или пользуйтесь инструментами Пиксель Тулс, Just-Magiс для определения коммерческости.
3. Выбор для продвижения очень конкурентных запросов. Позиции для ВЧ ВК фраз на 60-70% зависят от поведенческих факторов, а чтобы их получить нужно попасть в топ. Чем больше претендентов, тем длиннее очередь из желающих и выше требования к сайтам. Все, как в жизни или спорте. Стать чемпионом мира намного сложнее, чем получить тоже звание в своем городе. Поэтому лучше заходить в тихую, а не перегретую нишу.
Раньше оказаться на вершине было еще сложнее. В топе стояли по принципу кто успел, тот и съел. Лидеры попадали на первые места, а сместить их можно было только, накопив поведенческие факторы. А как их получить, если ты на второй или третьей странице… Яндекс разорвал этот замкнутый круг летом 2015 года, введя алгоритм «многорукий бандит». Суть его, как раз и состоит в том, чтобы рандомно повышать и понижать позиции сайтов, чтобы понять не появились ли более достойные кандидаты для нахождения в топе.
Сколько денег нужно для старта?
Чтобы ответить на этот вопрос посчитаем затраты на необходимый арсенал программ и сервисов, чтобы подготовить и разгруппировать ключевые фразы на 100 статей.
Самый минимум (подойдет для классического варианта):
1. Словоеб — бесплатно 2. Majento кластеризатор — бесплатно 3. На распознавание каптч — 30 руб. 4. Xml-лимиты — 70 руб. 5. Проверка конкуренции запроса по Мутагену — 10 проверок в день бесплатно 6. Если вы никуда не торопитесь и готовы потратить на парсинг 20-30 часов можно обойтись и без прокси. ————————— Итог — 100 рублей. Если вводить каптчи самому, а xml лимиты получить в обмен на переданные со своего сайта, то реально подготовить ядро вообще бесплатно. Нужно только потратить денек другой на настройку и освоение программ и еще 3-4 дня на ожидание результатов парсинга.
Стандартный набор семантиста (для продвинутого и классического метода):
1. Кей Коллектор — 1900 рублей 2. Кей Ассорт — 1700 рублей 3. Букварикс (бизнес-аккаунт) — 650 руб. 4. Сервис анализа конкурентов keys.so — 1500 руб. 5. 5 прокси — 350 рублей в месяц 6. Антикаптча — примерно 30 руб. 7. Xml-лимиты — около 80 руб. 8. Проверка конкуренции Мутагеном (1 проверка = 30 копеек) – уложимся в 200 руб. ———————- Итог — 6410 рублей. Можно конечно обойтись без KeyAssort, заменив его Majento кластеризатором и вместо Кей Колектора использовать Словоёб. Тогда хватит и 2810 рублей.
Стоит ли доверять разработку ядра «профи» или лучше разобраться и сделать самому?
Если человек регулярно занимается любимым делом, прокачивается в нем, то следуя логике, его результаты должны быть точно лучше, чем у новичка в этой сфере. А вот с подбором ключевиков все получается в точности наоборот.
Почему в 90% случаев новичок делает лучше профессионала?
Все дело в подходе. Задача семантиста не собрать для вас лучшее ядро, а выполнить свою работу за минимальный срок и чтобы ее качество вас устроило.
Если же вы делаете все сами по тем алгоритмам о которых говорилось раннее — результат будет на порядок выше по двум причинам:
- Вы разбираетесь в теме. Значит, знаете потребности ваших клиентов или пользователей сайта и сможете на начальном этапе максимально расширить маркерные запросы для парсинга, использовав большое количество синонимов и специфичных слов.
- Заинтересованы сделать все качественно. Владелец бизнеса или сотрудник компании в которой он работает конечно подойдет к вопросу более ответственно и постарается сделать все на максимум. Чем полнее ядро и больше низкоконкурентных запросов в нем, тем больше удастся собрать целевого трафика, а значит и прибыль при тех же вложениях в контент будет выше.
Как найти, оставшиеся 10%, которые составят ядро лучше вас?
Ищите компании у которых подбор ключевых фраз является ключевой компетенцией. И сразу обговариваете какой хотите результат, как у всех или максимум. Во втором случае, будет раза в 2-3 дороже, но в долгосрочной перспективе многократно окупится. Для тех кто хочет заказать услугу у меня, вся необходимая информация и условия тут. Качество гарантирую!
Почему так важно полностью прорабатывать семантику
Здесь, как и в любой сфере работает принцип «хорошего и плохого выбора». В чем его суть? Ежедневно мы сталкиваемся с тем, что выбираем:
- встречаться с человеком, который вроде бы ничего, но не цепляет или разобравшись в себе построить гармоничные отношения с тем кто нужен;
- заниматься работой которая не нравится или найти, то к чему лежит душа и сделать это своей профессией;
- арендовать помещение для магазина в не проходном месте или все-таки подождать пока освободится, подходящий вариант;
- взять в команду не лучшего менеджера по продажам, а того кто лучше всех себя показал на сегодняшнем собеседовании.
Вроде бы все понятно. А если посмотреть на это с другой стороны, представив каждый выбор, как инвестицию в будущее. Вот тут и начинается самое интересное!
Сэкономили на сем. ядре, 3-5 тысяч. Довольны, как слоны! Но к чему это приводит дальше:
а) для информационных сайтов:
- Потери по трафику минимум в 1,5 раза при тех же вложениях в контент. Сравнивая разные методы получения ключевых фраз, мы уже выяснили опытным путем, что альтернативный метод позволяет собирать на 51% больше;
- Проект быстрее проседает в выдаче. Конкурентам легко обойти нас, дав более полный ответ по интенту.
б) для коммерческих проектов:
- Меньше лидов или повышение их стоимости. Если у нас семантика, как у всех, то мы и продвигаемся по тем же запросам, что и конкуренты. Большое количество предложений при неизменном спросе уменьшает долю каждого из них на рынке;
- Низкая конверсия. Конкретные запросы лучше конвертируются в продажи. Экономя на сем. ядре, мы теряем самые конверсионные ключи;
- Тяжелее продвигаться. Много желающих быть в топе — выше требования к каждому из кандидатов.
Желаю, вам всегда делать хороший выбор и инвестировать только в плюс!